go字符串类型
go 用 string 来标识字符串类型,在了解字符串类型前,可以前往基础语法的 String literals ,了解字符串常量的内容。
字符串类型有以下特性:
string 底层是一个字节数组,是字符常量经过 UTF-8 编码之后的结果。
string 是不可变更(immutable)的,这点和 Java 一样。
string 类型没有方法,操作 string 的方法由 strings 包提供。
在赋值语句中,源字符串和目标字符串共享底层的字节数组;通过 substring 方法获得的子串和源字符串共享底层字节数组。
空字符串可以用
""和` `来表示。
1. 字符串操作
1.1 运算符
字符串支持的运算符有以下几种
+ += == != > < >= <=
string 是不可变的,故+、+=不会修改源字符串,而是生成一个新字符串。
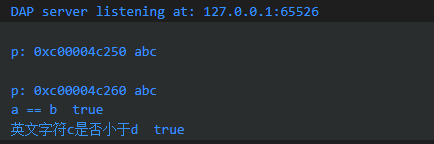
两个 string 的比较,实际是底层字节数组的比较。英文字符的 UTF-8 编码和 ascii 一致,因此英文字符的比较按照字典的顺序。特别需要说明的是: go 的==和 Java 的区别很大,Java 的==判断两个字符串地址是否相等,equals 方法才是判断字符串的内容是否相等。下面例子里,变量a和b的地址不同,但内容相同,打印a==b的结果为true。
package main
import "fmt"
func main() {
var a string = "abc"
var b string = "abc"
printStringAddr(&a)
printStringAddr(&b)
fmt.Printf("a == b %t", a == b)
var c string = "c"
var d string = "d"
fmt.Printf("\n英文字符c是否小于d %t", c < d)
}
func printStringAddr(s *string) {
fmt.Printf("\np: %p %v\n", s, *s)
}
1.2 字符串长度
通过len方法返回的长度是底层字节数组的长度,通过utf8.RuneCountInString返回的是 rune 的长度。下面例子里,一共三个字符,其中英文字符占一个字节(值与 ascii 一致),中文字符占三个字节。
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
var a string = "a好的"
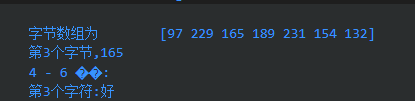
fmt.Printf("字节数组长度,%d", len(a))
b := []byte(a)
fmt.Printf("\n 字节数组为\t %v", b)
fmt.Printf("\n 字符长度 :%d ", utf8.RuneCountInString(a))
}

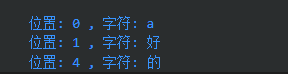
for range作用于字符串时,遍历的是字符,而非字节数组。
package main
import (
"fmt"
)
func main() {
var a string = "a好的"
for pos, char := range a {
fmt.Printf("\n位置: %d , 字符: %c", pos, char)
}
}
1.3 子串
string 底层是字节数组,因此可以使用下标来访问数组里的元素。s[i]表示字节数组里的第i个字节,并不是第i个字符串,同时s[i]无法被修改。
s[start:end]表示第start个字节(包含)到第end个字节(不包含),任何选取的[start,end)可能不是合法的 UTF-8 编码。获取第i个字符,需要先将 string 转为 rune 数组,然后再取第i个字符。
package main
import (
"fmt"
)
func main() {
var a string = "a好的"
b := []byte(a)
fmt.Printf("\n字节数组为\t %v", b) //打印字节数组
fmt.Printf("\n第3个字节,%d", a[2]) //第三个字节
fmt.Printf("\n4 - 6 %s:", a[3:5]) //两个字节是非法的UTF-8编码
fmt.Printf("\n第2个字符:%s", string([]rune(a)[1])) //第二个字符好
}