go基础语法
go 语法内容丰富,现精选一些常用语法进行介绍。
1. 代码评论
和其他编程语言类似,有两种形式:
- 以
//开始,到一行结束 - 以
/*开始,到最近的*/结束。
2. 语句结尾
go 以;作为语句结尾,但很多时候;可以省略。
3. 标识符
标识符是变量或者类型的名称,由字母和数字组成。go 里字母和数字的定义基于unicode 8.0。其中字母也包括_(U+005F),标识符的第一个必须是字母。下面都是合法的标识符。
a
_x9
ThisVariableIsExported
αβ
4. 关键字
下面是 go 定义的关键字,这些关键字无法被用作标识符。
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
5. 运算符
go 运算符定义如下。
+ & += &= && == != ( )
- | -= |= || < <= [ ]
* ^ *= ^= <- > >= { }
/ << /= <<= ++ = := , ;
% >> %= >>= -- ! ... . :
&^ &^= ~
go 没有三目运算符(ternary),官方的解释是if else可读性更强.
6. 整数
go 为非10进制数定义了前缀,二进制为0b或者0B;8进制为0或者0o或者0O;16进制为0x或者0X,单独的0表示10进制的0。在16进制下,a ~ f 和 A ~ F 表示10~15。为了方便阅读,允许加入_,但是下面这些例子并非合法的整数。
_42 //标识符
42_ //后面没有数字
4__2 //一次只能有一个_,这点和Java不同
0_xBadFace //_后面必须是合法的数字。
7. Rune literals
Rune literals 用来表示字符常量,在理解 Rune literals 之前,需要先理解 Unicode 。最早的字符编码是 ascii ,它用7比特来表示128个字符,包括英文字符大小写、数字等。随着计算机的广泛应用,字符越来越多,这显然不够。于是出现了 Unicode 编码。 Unicode 编码的思想和 ascii 类似,用一个数字来对应一个字符,这个数字被称为码点(Unicode Code Point)。最新的版本为14,一共144697个字符,需要一个32位的整数来表示这些码点。
存储和网络传输最终都是字节数组,所以需要将码点转换成字节数组,读取的时候解析数组就知道对应的码点,也就知道是什么字符了。可以直接用4个字节来表示一个码点,但使用频次非常高的 ascii 码其实只需要一个字节就可以,所以出现了 UTF-8、UTF-16 等编码方式。其中 UTF-8 广泛应用于互联网传输中,它用1~4个字节来表示一个码点。频次越高的字符,编码长度越短。这样极大的减少网络传输的带宽。下表是 UTF-8 的编码规则。
| 开始码点 | 结束码点 | 字节1 | 字节2 | 字节3 | 字节4 |
|---|---|---|---|---|---|
| U+0000 | U+007F | 0xxxxxxx | |||
| U+0080 | U+07FF | 110xxxxx | 10xxxxxx | ||
| U+0800 | U+FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| U+10000 | U+10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
回到 Rune literals,它实际是一个 int32,对应字符的码点。go 里用单引号'来标识 Rune literals,值可以为对应字符,也可以为对应码点。码点有四种表示方式:
\x后面2个16进制数\u后面4个16进制数\U后面8个16进制数\后面3个8进制数
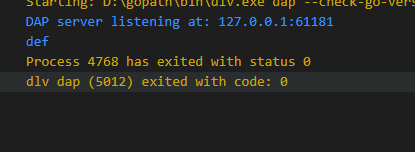
下面实测以下 Rune literals,细心的朋友可能已经发现:1、5、6其实是同一个,只是表示方式不同。
package main
import (
"fmt"
"reflect"
)
func main() {
// Creating a rune
rune1 := 'B' //使用字符本身
rune2 := 'g' //使用字符本身
rune3 := '\u2764' //小u后面4个16进制
rune4 := '\U0001F61A' //大U后面8个16进制
rune5 := '\x42'
rune6 := '\102'
// Displaying rune and its type
fmt.Printf("Rune 1: %c; Unicode: %U; Type: %s; int:%d", rune1,
rune1, reflect.TypeOf(rune1), rune1)
fmt.Printf("\nRune 2: %c; Unicode: %U; Type: %s, int : %d", rune2,
rune2, reflect.TypeOf(rune2), rune2)
fmt.Printf("\nRune 3 :%c; Rune 3: Unicode: %U; Type: %s;int : %d", rune3, rune3,
reflect.TypeOf(rune3), rune3)
fmt.Printf("\nRune4: %c;Rune 4: Unicode: %U; Type: %s; int :%d", rune4, rune4,
reflect.TypeOf(rune4), rune4)
fmt.Printf("\nRune5: %c;Rune 5: Unicode: %U; Type: %s; int :%d", rune5, rune5,
reflect.TypeOf(rune5), rune5)
fmt.Printf("\nRune6: %c;Rune 6: Unicode: %U; Type: %s; int :%d", rune6, rune6,
reflect.TypeOf(rune6), rune6)
}
执行结果如下:
8. String literals
go 里面的字符串分为两种:一种叫 raw string,一种叫 interpreted string。raw string 用左引号 ` 标识。左引号之间可以是任意字符(除了左引号),包括换行符。\没有特殊的含义(这是叫 raw 的原因,同时左引号无法转义)
`abc` // same as "abc"
`\n
\n` // same as "\\n\n\\n" 注意换行符
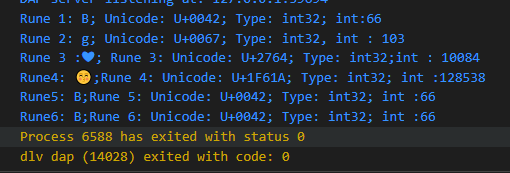
interpreted string 用双引号"标识,双引号之间不能有换行符、没有转义的双引号等。和 rune literals 一样,\会被解析,但两者含义有差异。在 interpreted string 中\nnn和\xnn会被解析成一个字节,并被当作某个字符 UTF-8 编码结果的某个字节;\u和\U则被解析为码点。下面以ÿ为例,它的码点为 U+00FF ,对应的 UTF-8 编码为\xc3\xbf。
package main
import (
"fmt"
"reflect"
)
func main() {
// Creating a rune
rune1 := '\377'
rune2 := '\xff'
rune3 := '\u00ff'
rune4 := '\U000000ff'
// Displaying rune and its type
fmt.Printf("Rune 1: %c; Unicode: %U; Type: %s; int:%d", rune1,
rune1, reflect.TypeOf(rune1), rune1)
fmt.Printf("\nRune 2: %c; Unicode: %U; Type: %s, int : %d", rune2,
rune2, reflect.TypeOf(rune2), rune2)
fmt.Printf("\nRune 3 :%c; Rune 3: Unicode: %U; Type: %s;int : %d", rune3, rune3,
reflect.TypeOf(rune3), rune3)
fmt.Printf("\nRune 4 :%c; Rune 4: Unicode: %U; Type: %s;int : %d", rune4, rune4,
reflect.TypeOf(rune4), rune4)
s1 := "\u00ff"
s2 := "\U000000ff"
s3 := "\xff"
s4 := "\377"
s5 := "\xc3\xbf"
s6 := "\303\xbf"
fmt.Printf("\n s1 : %s", s1)
fmt.Printf("\n s2 : %s", s2)
fmt.Printf("\n s3 : %s", s3)
fmt.Printf("\n s4 : %s", s4)
fmt.Printf("\n s5 : %s", s5)
fmt.Printf("\n s6 : %s", s6)
}
上面代码定义了4个 rune,6个 interpreted string 。其中4个 rune literals 都表示 U+00FF 这个码点。在 interpreted string 里\u和\U被解析成为码点,但\nnn和\xnn被解析成为了一个字节,并且是某个字符 UTF-8 结果里面的某个字节(s5 和 s6) 。
9. named return values
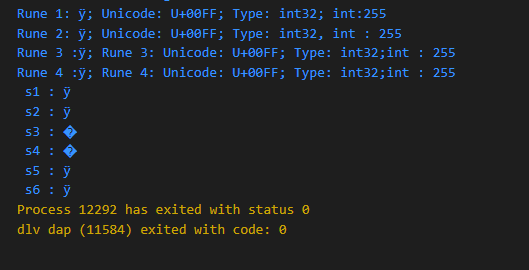
go 允许像参数一样,给返回值命名并使用它。在函数开始时,命名的返回值被初始化为对应类型的0值,在函数执行过程中,可以修改命名的返回值,如果return语句没有参数,命名返回值的结果会返回给调用者。
package main
import "fmt"
func namedReturn1(a, b int) (sum int) {
sum = a + b
return
}
func namedReturn2(a, b int) (sum int) {
return a * b
}
func main() {
a := 5
b := 10
fmt.Printf("\nnamed return 1 result : %d", namedReturn1(a, b))
fmt.Printf("\nnamed return 2 result : %d", namedReturn2(a, b))
}
命名返回值的优点有:
它可以作为函数的注释,返回值的命名可以清楚的告诉调用方每一个返回值的含义。
它是自动声明并初始化为0的。
它允许
defer函数捕获原函数的返回值,并修改返回值(可用于处理 panic 等)。
package main
import "fmt"
func namedReturn() (s string) {
defer func() {
if s == "abc" {
s = "def"
}
}()
return "abc"
}
func main() {
fmt.Println(namedReturn())
}